
AI로 관리비·공과금 내역 분석하고 아끼는 법 2026 — 여름 전기요금 폭탄 막기
관리비 고지서, 매달 금액만 보고 그냥 내셨죠. 고지서를 AI에 넣으면 항목별로 뜯어서 전월 대비 어디가 늘었는지, 아낄 여지는 어딘지 짚어줘요. 고지서 읽히는 법, 항목 분석 프롬프트, 매달 자동 비교 루틴, 2026년 여름 누진제 완화·에너지캐시백까지 정리했어요.
AI 기술을 누구나 쉽게 활용할 수 있도록 실전 가이드를 작성합니다. ChatGPT, Claude, AI 자동화, SEO 분야를 전문으로 다룹니다.
Make에 시나리오를 하나둘 만들다 보면 어느새 수십 개가 쌓여 있죠. 본인도 그랬어요. 처음엔 메일 자동 분류 하나로 시작했는데, 어느 날 세어보니 30개가 넘더라고요. 그러다 한 시나리오가 멈췄는데, 그게 어디까지 영향을 주는지 도저히 머릿속에서 그려지지 않았어요.
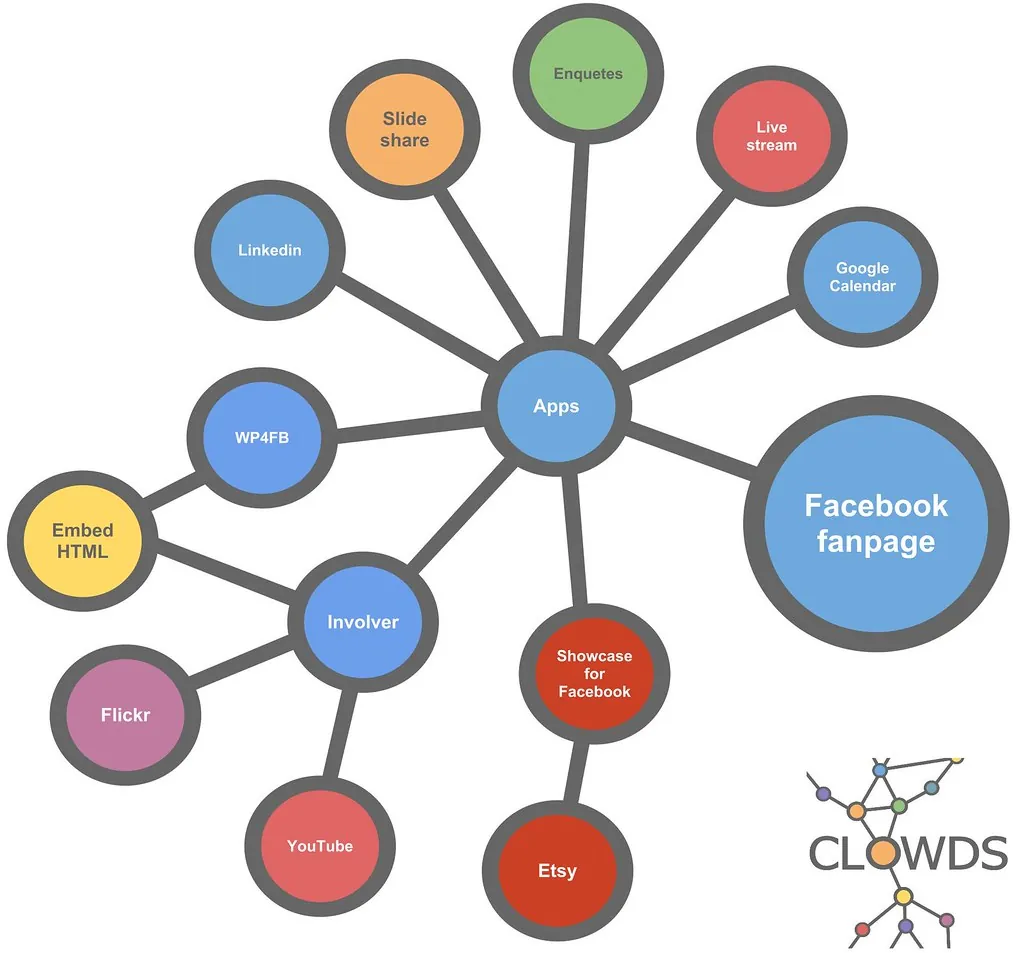
Make가 2026년에 추가한 Make Grid가 바로 이 문제를 노린 기능이에요. 조직 안에 흩어진 자동화 시나리오 전체를 실시간 지도로 자동으로 그려줘요. 어떤 시나리오가 어떤 데이터 흐름으로 연결됐는지, 서로 어떤 의존 관계인지가 한 화면에 펼쳐져요. Make는 2026년에 Maia(자연어 시나리오 빌더)와 Make AI Agents에 이어 이 Grid를 더했고, 모든 유료 플랜에 포함시켰어요.
이번 글은 본인이 실제로 30개 넘는 시나리오를 Grid로 펼쳐보면서 정리한 5단계 실전 가이드예요. 죽은 자동화 찾기, 중복 제거, 장애 추적까지 직접 해본 기준으로 다뤄요. n8n·Zapier와 어떻게 다른지도 같이 짚을게요.
가장 먼저 할 일은 그냥 Grid를 열어 전체 그림을 보는 거예요. Make Grid는 유료 플랜에 포함돼서, 별도 설정 없이 기존 시나리오를 자동으로 지도화해줘요. 본인은 처음 켰을 때 화면을 캡처부터 했어요.
왜 캡처냐면, 정리 전후를 비교하려고요. 본인 노하우 — 정리 작업은 한 번에 끝나지 않아요. 죽은 시나리오를 비활성화하고 2주 뒤 다시 보면 지도가 달라져 있거든요. 처음 상태를 사진으로 남겨두면, "내가 뭘 지웠고 뭘 합쳤는지"를 나중에 추적할 수 있어요.
본인 체감 — 첫 캡처를 보자마자 충격이었어요. 30개 넘는 노드가 거미줄처럼 얽혀 있는데, 그중 절반은 본인도 "이게 뭐였더라" 싶은 시나리오였어요. 머릿속으로만 관리하던 게 얼마나 위험했는지 그림으로 보니까 바로 와닿았어요.
Grid를 처음 보는 분이 헷갈리는 부분이 하나 있어요. 노드가 시나리오고, 노드 사이를 잇는 화살표가 데이터 흐름이에요. A 시나리오가 만든 결과를 B 시나리오가 받아 쓰면 둘 사이에 화살표가 그려져요. 본인 노하우 — 처음엔 이 화살표만 따라가도 충분해요. 화살표가 많이 모이는 노드는 중요한 허브고, 화살표가 하나도 없는 노드는 외딴 섬이거든요. 색이나 굵기 같은 세부 표시는 나중에 익히고, 일단 '연결의 모양'부터 눈에 담으세요.
본인은 첫 주에 이 지도를 출력해서 책상에 붙여뒀어요. 며칠 들여다보니 "아, 이 두 시나리오가 사실 같은 일을 하고 있었네" 같은 발견이 계속 나왔어요. 머릿속에서는 절대 안 보이던 패턴이 종이 한 장으로 보이기 시작한 거예요.
다음은 오래 안 돈 시나리오를 찾는 거예요. Grid는 각 노드에 마지막 실행 시점과 실행 빈도를 함께 표시해요. 본인은 '최근 실행 없음'이거나 실행 횟수가 0에 가까운 노드부터 표시했어요.
본인 실측 — 6개월간 한 번도 안 돈 죽은 시나리오가 4개나 있었어요. 옛날 이벤트용으로 만들었다가 잊은 것, 테스트하다 끄지 않은 것 같은 거였어요. 이런 게 살아 있으면 오퍼레이션(작업 실행 횟수)을 조용히 갉아먹거나, 엉뚱하게 한 번씩 돌아 사고를 내요.
본인 노하우 — 죽은 것 같아도 바로 지우지 마세요. 일단 'OFF'로 비활성화하고 2주를 지켜봐요. 분기 정산·연말 보고처럼 가끔 도는 시나리오를 죽은 걸로 오해해서 지우면 나중에 곤란해지거든요. 2주 동안 아무도 안 찾으면 그때 삭제해요.
비활성화와 삭제를 구분하는 게 핵심이에요. 비활성화는 시나리오를 잠시 멈추는 거라 언제든 되돌릴 수 있어요. 삭제는 영구적이고요. 본인은 한 번 성급하게 지운 시나리오 때문에 처음부터 다시 만든 적이 있어서, 그 뒤로는 무조건 '비활성화 → 관찰 → 삭제' 3단계를 지켜요. 자동화는 한 번 지우면 그 안의 설정·연결·필터를 다시 짜야 하는데, 그게 만드는 것보다 더 귀찮거든요.
본인 노하우 한 가지 더 — 비활성화할 때 시나리오 이름 앞에 'OFF_'나 날짜를 붙여둬요. 그러면 나중에 Grid에서 "이건 내가 일부러 끈 거"라는 게 한눈에 보여요. 끈 이유를 메모에 적어두면, 2주 뒤 다시 봤을 때 "왜 껐더라" 하고 고민할 필요도 없고요.

Grid의 진짜 가치는 '관계'가 보인다는 데 있어요. 본인은 두 종류를 노렸어요. 하나는 중복, 하나는 고아예요.
중복은 같은 일을 두 번 하는 시나리오예요. 본인 실측 — 같은 구글 시트를 두 군데서 갱신하던 중복 자동화 2쌍을 찾았어요. 예전에 비슷한 걸 새로 만들면서 옛날 것을 안 끈 거였어요. 둘 다 돌면 데이터가 꼬이거나 오퍼레이션만 두 배로 들어요. 하나로 합쳤어요.
고아는 어디와도 연결 안 된 외딴 시나리오예요. 데이터를 받지도, 어디로 보내지도 않는 노드요. 본인 노하우 — 고아 노드는 보통 둘 중 하나예요. 정말 독립적으로 잘 돌고 있거나, 연결이 끊겨서 무용지물이 됐거나. 화살표를 따라가며 확인하고, 끊긴 거면 고쳐 잇거나 지웠어요.
중복을 합칠 땐 순서가 있어요. 본인은 (1) 두 시나리오 중 더 최근에 만들고 잘 도는 쪽을 '남길 것'으로 정하고, (2) 다른 쪽에만 있는 설정·필터가 있는지 비교해서 남길 쪽에 옮기고, (3) 옮긴 게 잘 도는지 한 번 테스트한 뒤, (4) 그제야 옛 시나리오를 비활성화해요. 이 순서를 안 지키고 그냥 하나를 지웠다가, 거기에만 있던 예외 처리 필터가 사라져서 데이터가 새는 사고를 본인이 한 번 겪었거든요.
본인 체감 — 중복 2쌍을 합치니 오퍼레이션이 눈에 띄게 줄었어요. 같은 시트를 두 번 갱신하던 게 한 번으로 줄었으니 당연한 결과죠. 자동화는 많이 만드는 게 잘하는 게 아니라, 꼭 필요한 것만 깔끔하게 도는 게 잘하는 거예요.
지도를 보면 어떤 시나리오가 '허브'인지 보여요. 여러 화살표가 모이고 갈라지는 중심 노드요. 본인은 이 허브 시나리오에 우선순위를 두고 실패 알림을 따로 걸었어요.
본인 노하우 — 허브가 멈추면 거기 연결된 여러 자동화가 줄줄이 영향을 받아요. 그래서 허브일수록 빨리 알아야 해요. Make의 에러 핸들러나 알림 모듈로, 이 시나리오가 실패하면 즉시 슬랙·메일로 통보가 오게 설정했어요.
본인 체감 — 예전엔 자동화가 멈춰도 며칠 뒤에야 "어, 이 데이터가 왜 안 들어왔지" 하고 알았어요. Grid로 허브를 식별하고 알림을 건 뒤로는, 멈추는 즉시 알게 돼서 복구가 빨라졌어요. 모든 시나리오에 알림을 걸 필요는 없고, 지도상 영향력이 큰 것부터 거는 게 효율적이에요. 자동화 보안 전반을 점검하려면 자동화에서 개인정보 유출 막는 가드레일 설정법도 같이 보면 도움이 돼요.
마지막은 습관이에요. Grid는 한 번 보고 끝나는 도구가 아니라, 정기적으로 들여다봐야 효과가 쌓여요. 본인은 월 1회 청소 루틴을 만들었어요.
순서는 이래요. (1) Grid를 열어 전체 지도 캡처, (2) 안 도는·중복·고아 노드 표시, (3) 죽은 건 비활성화 후 2주 관찰 뒤 삭제, (4) 중복은 합치기, (5) 허브엔 실패 알림 점검. 매달 10분이면 충분해요.
본인 실측 — 이 루틴을 3개월 돌리니 시나리오가 30개에서 22개로 줄었어요. 개수가 줄면 오퍼레이션 비용도 줄고, 무엇보다 머릿속이 가벼워져요. 자동화도 창고랑 똑같아요. 안 치우면 쓰레기가 쌓이고, 정작 필요한 걸 못 찾게 돼요.
이 루틴을 달력에 고정 일정으로 넣어두는 걸 추천해요. 본인은 매월 첫째 주 월요일 오전을 'Grid 청소 시간'으로 잡았어요. 안 정해두면 "다음에 해야지" 하다가 또 시나리오가 쌓이거든요. 10분짜리 일이지만 정기적으로 해야 효과가 누적돼요. 한 번 크게 정리하고 끝내는 게 아니라, 매달 조금씩 깎아내는 게 핵심이에요.
본인 노하우 — 청소할 때 캡처해둔 지도를 지난달 것과 나란히 비교하면 변화가 보여요. 노드가 늘었으면 "이번 달에 뭘 새로 만들었지", 줄었으면 "뭘 정리했지"를 한눈에 알 수 있어요. 이 비교 자체가 자동화 운영을 되돌아보는 좋은 습관이 돼요. 어떤 플랫폼을 쓸지 고민 중이라면 Zapier vs Make vs n8n 가격·기능 비교를 먼저 읽어보세요.
Grid를 쓰다 보면 예상 못 한 발견이 또 있어요. 바로 '숨은 의존 관계'예요. A 시나리오가 멈추면 그 결과를 받던 B, B를 받던 C까지 줄줄이 영향을 받는데, 머릿속으로는 A밖에 안 보여요. Grid는 이 연쇄를 화살표로 다 그려주거든요.
본인 실측 — 한 번은 데이터를 가공하는 시나리오 하나를 무심코 끄려다, Grid에서 그게 세 개의 다른 시나리오에 데이터를 공급하고 있는 걸 봤어요. 그냥 껐으면 세 개가 동시에 망가질 뻔했어요. 지도가 없었으면 절대 몰랐을 관계예요.
본인 노하우 — 그래서 시나리오를 끄거나 고치기 전엔 항상 Grid에서 '이 노드에서 나가는 화살표'를 먼저 확인해요. 나가는 화살표가 많은 노드일수록 건드릴 때 조심해야 해요. 반대로 들어오는 화살표만 있고 나가는 게 없는 노드는 '종착지'라 비교적 안전하게 손댈 수 있고요. 이 방향 감각 하나만 익혀도 자동화 사고를 크게 줄여요.
시나리오가 10개를 넘었다면, 오늘 Make Grid를 한 번 열어보세요. 그리고 전체 지도를 캡처한 다음, 가장 오래 안 돈 노드 3개를 찾아 'OFF'로 꺼보세요. 그게 시작이에요.
Make Grid는 새 자동화를 만드는 도구가 아니라, 이미 만든 자동화를 위에서 내려다보게 해주는 관리자의 망원경이에요. n8n으로 워크플로를 깊게 짜고 Zapier로 흐름을 설계하더라도, '내 자동화 전체가 지금 어떻게 얽혀 있나'는 따로 봐야 하거든요. 월 10분의 청소 습관 하나가 자동화 비용과 사고를 같이 줄여줘요.
Make Grid는 Make가 2026년에 추가한 시각적 오케스트레이션 기능이에요. 조직 안에 흩어진 자동화 시나리오 전체를 실시간 지도로 자동 생성해줘요. 어떤 시나리오가 어떤 데이터 흐름으로 연결돼 있는지, 서로 어떤 의존 관계인지를 한 화면에서 보여줘요. Make는 2026년에 Maia(자연어 시나리오 빌더)·Make AI Agents(자율 에이전트)와 함께 이 Grid를 더했어요. 핵심 배경은 '시나리오가 많아지면 사람이 전체 그림을 못 본다'는 문제예요. Grid는 모든 유료 플랜에 포함돼서, 별도 요금 없이 기존 시나리오를 자동으로 지도화해줘요.
본인 체감으로는 10개를 넘어가면 효과가 확 와닿아요. 5~6개일 때는 머릿속에서도 정리가 되는데, 20~30개가 쌓이면 '이 시나리오가 끊기면 어디까지 영향이 가지?'를 따지기 어려워지거든요. 본인은 30개 넘는 시나리오를 운영 중이었는데, Grid를 켜자마자 6개월간 한 번도 안 돈 죽은 시나리오 4개랑, 같은 시트를 두 번 갱신하던 중복 자동화 2쌍이 바로 눈에 띄었어요. 시나리오가 적으면 굳이 안 봐도 되지만, 늘어나는 추세라면 일찍부터 습관 들이는 게 나중에 정리 비용을 줄여요.
Grid는 각 시나리오의 마지막 실행 시점과 실행 빈도를 노드에 함께 표시해요. 본인 노하우 — 지도에서 '최근 실행 없음'이나 실행 횟수가 0에 가까운 노드를 먼저 골라내요. 그다음 그 노드가 다른 시나리오와 연결돼 있는지 화살표로 확인하고요. 어디와도 연결 안 됐고 오래 안 돌았으면 죽은 자동화일 가능성이 높아요. 다만 바로 지우진 마세요. 본인은 일단 'OFF'로 비활성화하고 2주를 지켜본 뒤, 아무도 안 찾으면 삭제해요. 분기·연말처럼 가끔 도는 시나리오를 죽은 걸로 오해해 지우는 사고를 막기 위해서예요.
n8n은 시나리오 안의 워크플로 자체를 노드로 자유롭게 짜는 데 강점이에요. 2026년 n8n 2.0은 LangChain 통합과 70개 넘는 AI 노드로 에이전트를 깊게 만들 수 있고요. Zapier는 Canvas로 자동화 흐름을 그림으로 설계·문서화하는 쪽이에요. Make Grid의 차별점은 '이미 만들어 둔 시나리오 전체'를 자동으로 지도화한다는 거예요. 본인 비교 체감 — n8n·Zapier가 '하나의 자동화를 잘 설계하는' 도구라면, Make Grid는 '수십 개 자동화가 서로 어떻게 얽혔는지 위에서 내려다보는' 관리자 시점에 가까워요. 셋은 경쟁이라기보단 보는 층위가 달라요.
직접적인 보안 기능은 아니지만, 가시성이 보안에 도움이 돼요. 본인 노하우 — Grid에서 어떤 시나리오가 어떤 앱·외부 서비스에 연결돼 있는지 한눈에 보이니까, '쓰지도 않는데 권한만 살아 있는 연결'을 찾아 정리할 수 있어요. 본인은 Grid로 옛 마케팅 도구에 아직 연결된 시나리오 1개를 발견해 끊었어요. 안 쓰는 연결이 살아 있으면 그게 다 공격 표면이 되거든요. 가시성 → 불필요한 연결 정리 → 공격 표면 축소, 이 흐름으로 간접적인 보안 효과를 봐요.
본인 루틴은 월 1회예요. (1) Grid를 열어 전체 지도를 캡처해두고, (2) 안 도는 노드·중복 노드·고아 노드(어디와도 연결 안 된 시나리오)를 표시하고, (3) 죽은 건 비활성화 → 2주 관찰 → 삭제, (4) 중복은 하나로 합치고, (5) 핵심 시나리오엔 실패 알림을 따로 걸어요. 본인 체감 — 매달 10분만 들여도 시나리오 개수가 30개에서 22개로 줄었고, 그만큼 작업 실행량(오퍼레이션) 비용도 아꼈어요. 청소하지 않으면 자동화도 창고처럼 쓰레기가 쌓여요.
Grid는 모든 유료 플랜에 포함되는 기능이에요. 본인 확인 기준 — 무료(Free) 플랜에서는 시나리오 개수 자체가 제한적이라 Grid의 효용도 크지 않아요. 시나리오가 적을 땐 굳이 지도가 필요 없으니까요. 본인 노하우 — Core 같은 가장 낮은 유료 플랜부터 Grid가 켜지니, 시나리오가 10개를 넘기 시작하고 유료로 올라갈 시점이 되면 자연스럽게 Grid도 함께 쓰게 돼요. 요금제·제공 범위는 시점마다 바뀌니, 실제로는 본인 계정의 플랜 화면에서 Grid 항목이 보이는지 확인하는 게 정확해요.
관리비 고지서, 매달 금액만 보고 그냥 내셨죠. 고지서를 AI에 넣으면 항목별로 뜯어서 전월 대비 어디가 늘었는지, 아낄 여지는 어딘지 짚어줘요. 고지서 읽히는 법, 항목 분석 프롬프트, 매달 자동 비교 루틴, 2026년 여름 누진제 완화·에너지캐시백까지 정리했어요.

결혼식·돌잔치·부고·부모님 생신을 뒤늦게 알고 마음 상한 적 있으시죠? 기념일 정보를 한곳에 모아 며칠 전 자동 알림을 받고, AI로 축하·위로 메시지 초안까지 만들면 이 걱정이 사라져요. 캘린더·노션으로 리마인더 거는 법, 관계별 축의금 예산 관리, 메시지 프롬프트, AI가 놓치는 지점까지 제가 세팅한 순서대로 정리했어요.

매뉴얼 100개, 계약서 수십 건을 하나씩 번역기에 붙여넣다 하루가 다 가시죠? 폴더에 파일을 넣으면 자동으로 번역돼 나오게 만들면 이 반복이 사라져요. 번역 엔진 고르기부터 Make·n8n로 뼈대 짜기, 용어집으로 일관성 잡기, 비용 계산, 사람 검수까지. 대량 문서 번역을 자동화하는 전체 흐름을 제가 써본 순서대로 정리했어요.

여름 휴가 다녀와서 정산 때문에 애매해진 적 있으시죠. 누가 뭘 더 내고 누가 한 끼 빠졌는지까지 반영해서, AI에 내역만 붙여넣으면 사람별 정산표와 정산 요청 메시지가 한 번에 나와요. 내역 모으는 법, 불균등 N빵 프롬프트, 검산 요령, 계좌 주의점까지 직접 돌려보고 정리했어요.

AI 부업으로 월 30만원을 벌어도 손에 쥐는 건 훨씬 적어요. 도구 구독료·플랫폼 수수료·세금을 빼야 진짜 순이익이 나오거든요. 건당 실수령액과 손익분기 건수를 계산하는 공식, 3가지 부업 시뮬레이션 표, 흑자를 앞당기는 법까지 2026년 기준으로 정리했어요.